De Magie van de Normaalvergelijking in Lineaire Regressie Ontsloten
Stel je voor: je hebt een berg data en je wilt de toekomst voorspellen. Klinkt als magie, toch? Met de normaalvergelijking in lineaire regressie kom je een heel eind! Deze krachtige techniek is als een geheime formule die je helpt patronen in je data te ontrafelen en nauwkeurige voorspellingen te doen.
Lineaire regressie is een statistische methode om de relatie tussen variabelen te modelleren. De normaalvergelijking biedt een elegante oplossing voor het vinden van de optimale parameters van het lineaire model zonder iteratieve methoden zoals gradient descent. Het is een directe, wiskundige aanpak die de beste lijn door je data berekent.
Maar hoe werkt deze magische formule precies? De normaalvergelijking is een wiskundige vergelijking die je direct de beste waarden voor de coëfficiënten in je lineaire model geeft. Dit in tegenstelling tot andere methoden die iteratief naar de optimale oplossing zoeken. Denk aan het vinden van de kortste route naar je bestemming: de normaalvergelijking geeft je die route direct, zonder omwegen.
De normaalvergelijking is een essentieel onderdeel van machine learning en statistische modellering. Het is een krachtig instrument voor data-analyse en het maken van voorspellingen op basis van gegevens. Van het voorspellen van huizenprijzen tot het optimaliseren van marketingcampagnes, de normaalvergelijking is een onmisbare tool.
In dit artikel duiken we dieper in de wereld van de normaalvergelijking in lineaire regressie. We verkennen de theorie achter deze methode, bekijken praktische voorbeelden en bespreken de voor- en nadelen. Klaar om de geheimen van de normaalvergelijking te ontrafelen?
De normaalvergelijking vindt zijn oorsprong in de lineaire algebra en is al decennia lang een fundamenteel onderdeel van statistische analyse. Het belang ervan ligt in de efficiëntie en de directe oplossing die het biedt voor lineaire regressieproblemen. Een belangrijk probleem dat echter kan ontstaan is de computationele complexiteit bij zeer grote datasets, omdat de matrixinversie die nodig is voor de normaalvergelijking rekenintensief kan zijn.
De normaalvergelijking wordt gedefinieerd als: θ = (XTX)-1XTy. Waarbij θ de vector van modelparameters is, X de matrix van inputvariabelen, y de vector van outputvariabelen en T staat voor de getransponeerde matrix en -1 staat voor de inverse matrix.
Een eenvoudig voorbeeld: stel je wilt de relatie tussen het aantal studieuren en de behaalde cijfers modelleren. Met de normaalvergelijking kun je de beste rechte lijn vinden die deze relatie beschrijft, zodat je op basis van studieuren een voorspelling kunt doen over het te behalen cijfer.
Voordelen van de normaalvergelijking zijn: 1. Geen iteratie nodig, dus snelle berekening. 2. Geen leertempo (learning rate) nodig, zoals bij gradient descent. 3. Direct de optimale oplossing.
Voor- en Nadelen van de Normaalvergelijking
| Voordelen | Nadelen |
|---|---|
| Snelle berekening | Computationeel intensief bij grote datasets |
| Geen learning rate nodig | Niet geschikt voor niet-lineaire problemen |
| Directe optimale oplossing | Gevoelig voor multicollineariteit |
Veelgestelde vragen:
1. Wat is de normaalvergelijking? Antwoord: Een wiskundige vergelijking om de optimale parameters van een lineair model te vinden.
2. Wanneer gebruik je de normaalvergelijking? Antwoord: Bij lineaire regressieproblemen, vooral bij kleinere datasets.
3. Wat zijn de voordelen? Antwoord: Snel, geen learning rate nodig, directe oplossing.
4. Wat zijn de nadelen? Antwoord: Computationeel intensief bij grote datasets.
5. Hoe bereken je de normaalvergelijking? Antwoord: Met de formule θ = (XTX)-1XTy.
6. Wat is multicollineariteit? Antwoord: Een hoge correlatie tussen inputvariabelen.
7. Is de normaalvergelijking altijd de beste methode? Antwoord: Niet altijd, bij zeer grote datasets zijn iteratieve methoden vaak efficiënter.
8. Waar kan ik meer informatie vinden? Antwoord: Zoek online naar 'normal equation linear regression'.
Tips en trucs: Controleer altijd op multicollineariteit in je data. Overweeg alternatieve methoden zoals gradient descent bij zeer grote datasets.
De normaalvergelijking is een krachtige tool voor lineaire regressie. Het biedt een directe en efficiënte manier om de optimale parameters van je model te vinden, waardoor je accurate voorspellingen kunt doen. Hoewel het computationele uitdagingen kan opleveren bij grote datasets en gevoelig is voor multicollineariteit, blijft het een waardevolle techniek voor data-analyse en machine learning. Door de voor- en nadelen te begrijpen en de beste praktijken te volgen, kun je de kracht van de normaalvergelijking optimaal benutten en waardevolle inzichten uit je data halen. Duik dieper in de wereld van lineaire regressie en ontdek de mogelijkheden van de normaalvergelijking!
Vind de juiste woorden synoniemen voor spoor
White nike shin guards bescherm je benen in stijl
Waardering tonen voor goede zorg

Linear Regression With n Features | Solidarios Con Garzon

normal equation linear regression | Solidarios Con Garzon

normal equation linear regression | Solidarios Con Garzon

Normal Equation for Linear Regression | Solidarios Con Garzon

Normal Equation in Linear Regression | Solidarios Con Garzon
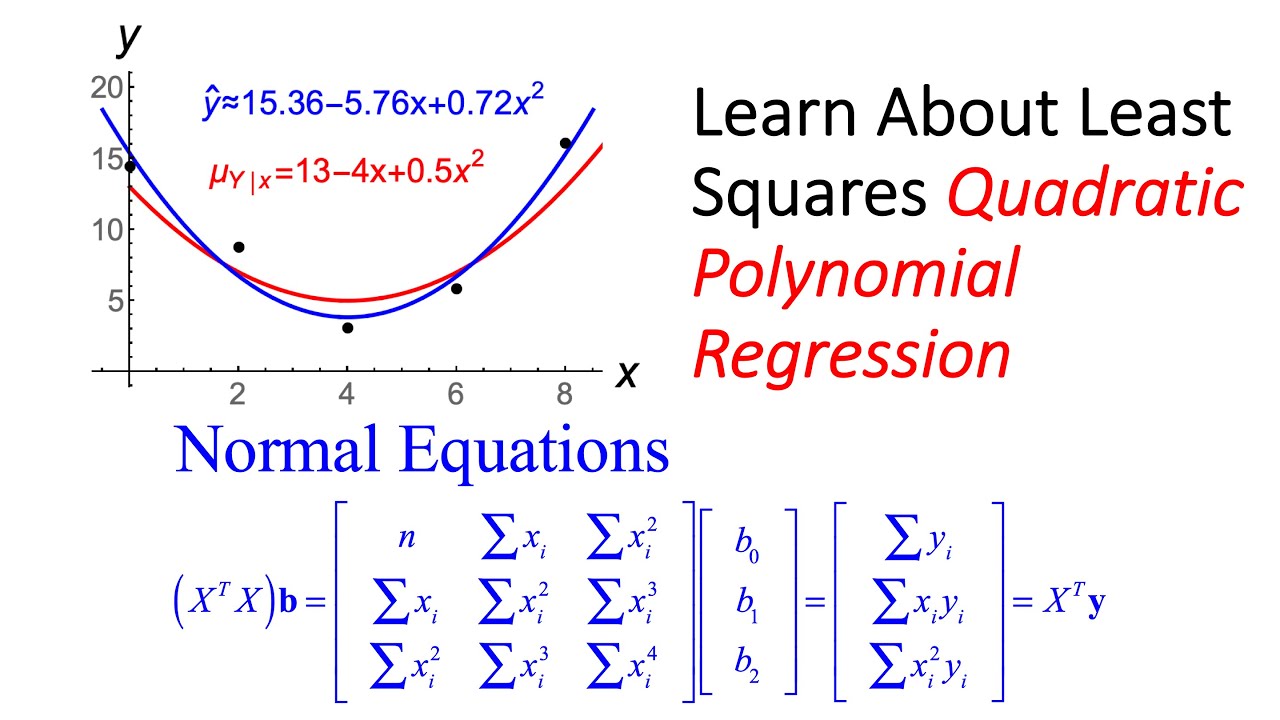
Second order regression excel | Solidarios Con Garzon

Multiple features Linear Regression with multiple variables | Solidarios Con Garzon

Multiple linear regression equation example | Solidarios Con Garzon

Performing linear regression using the normal equation | Solidarios Con Garzon

Normal Equation of Linear Regression | Solidarios Con Garzon

Multiple features Linear Regression with multiple variables | Solidarios Con Garzon

Linear Regression e The Normal Equation | Solidarios Con Garzon

The Normal Equation Proof | Solidarios Con Garzon

Normal Equation for Linear Regression Tutorial | Solidarios Con Garzon

Linear Regression The Normal Equation | Solidarios Con Garzon